Kubernetes 101 : Performing tasks in kubernetes - Jobs -
To make sure an application runs until it is done, we use a kubernetes object called a Job controller, that will make sure the application runs until it finishes its task.
Jobs are meant for programs that perform a specific task then exit.
Non-parallel jobs:
Non-parallel Jobs run one pod, if the pod fails, another one is deployed to replace it.
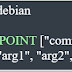
Below is the Yaml configuration file of a Job running an "ls" command inside a "debian" container, then exiting:

restartPolicy : it tells kubernetes whether the Job should be restarted "OnFailure". The other option is "never".
backoffLimit: is the number of times the Job will try to restart a failing pod.
backoffLimit: is the number of times the Job will try to restart a failing pod.
Remark: There are no pod labels.
We can then create our Job using the below command:

Watching our Job:
We can watch the pod until it exits using the below command:

We can see that the pod goes from Running to the Completed state.
Getting the logs from the Job:
We can get the logs of the Job pod, since it is not deleted after it finishes.
We could do so using the below command:

Sequential jobs:
We can run Jobs one after the other (sequentially) using the below Yaml configuration file:

completions: three Jobs need to complete their execution.
Parallel jobs:
We could also run Jobs in parallel at the same time using the below Yaml configuration file:

completions: eight Jobs need to complete their execution.
parallelism: maximum of Jobs that can run at the same time (in parallel).
Displaying the jobs:
We could display the Jobs in our cluster using the below command:

Scheduling jobs:
In case we want to run our Jobs periodically, we would need to use another kubernetes object called a CronJob.









Comments