Kubernetes 101 : The lifecycle of a Pod - Pending, Creating, Running and CrashLoopBackOff -
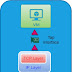
When we create a pod, it goes into a "Pending" state. Kubernetes is aware of the pod's existence but it hasn't yet been scheduled on any worker node.
The scheduler looks at the pod's requirements and tries to find a suitable host that matches or exceeds these requirements.
Once the scheduler finds suitable match for the pod's requirements, the pod transitions to the "Creating" state.
The node pulls the image from the images registry.

Remark:
Kubernetes usually schedules a pod on a node that already has its image to save time and resources.
After the image is pulled and executed, the pod moves into a "Running" state.
If the pod crashes, kubernetes restarts it.
When the "crashing" pod is restarted too many times without success, it goes into a "CrashLoopBackoff" state, which means that kubernetes will not try to restart the pod immediately, but it will wait for some time before restarting it.
The waiting period gets longer each time kubernetes tries to restart the pod and fails.
The states of a pod:
We can see the states of the pods by running the below command:

When we have issues with the pod, we could look at its log using the below command:

We could also watch the pod "live":


Persistent pending state:
A persistent "pending" state means that the scheduler couldn't schedule the pod on any host. This usually happens because of lack of resources ( RAM, CPU, ... ).
A solution would be to delete some pods, to free up resources, or to scale up the cluster for example.
Persistent creating state:
A persistent "Creating" state is usually caused by an issue with the image, because the node is unable to pull the image from the registry.
Because the pod is not created yet, we can't use the below command to see the pod's state:

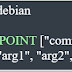
We will use the "describe" command instead as described below:










Comments