Kubernetes 101 : Headless services
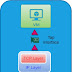
When a client makes a request it is routed through the Cluster IP service to one of the endpoint pods replicas that are members of the Cluster IP service.

IP addresses and port above are given as an example.
Clients, for example other pods, need to go through the Cluster IP service in red to communicate with the blue pods.
The cluster IP forwards the request from the client to one of the blue
pods.
What is a pod wants to communicate directly with another pod?
For the Stateful applications like databases the replicas are not the same, pods need to communicate directly with specific pods, because the Cluster IP service send requests "randomly" to any pod in its group.
Database pods:
For database pods, we have master pods and worker (slave) pods.
The worker connects to the master directly to synchronize its data.
When a new database pod is added, it connects to the last pod to update its data. So pods need to have direct communication to other pods.

In the above diagram, when we add the DB-4 pod, the DB-4 pod needs to connect directly to the DB-3 pod to be able to replicate its data through synchronization
We will start by assigning "none" in the Cluster IP field in the YAML file.

When a pod does a DNS lookup, it will receive the IP address of the pod instead of the IP address of the Cluster IP service.
The role of the service is to do a DNS lookup and give the requesting pod the IP address of the destination pod, so they could communicate directly without going through the cluster IP service.

The headless service creates a DNS record for its member pods.
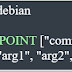
We can see the headless service by using the below command:
If a pod crashes, it gets re-deployed with a new IP address, the replacement pod will keep the same hostname but it will be tied to the new pod IP address.









Comments